# Tensorflow 基础框架
# 处理结构
计算图纸
Tensorflow 首先要定义神经网络的结构,然后再把数据放入结构当中去运算和 training.

因为 TensorFlow 是采用数据流图(data flow graphs)来计算,所以首先我们得创建一个数据流流图,然后再将我们的数据(数据以张量 (tensor) 的形式存在)放在数据流图中计算。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor). 训练模型时 tensor 会不断的从数据流图中的一个节点 flow 到另一节点,这就是 TensorFlow 名字的由来.
# 例子 1
tensorflow version 1 代码如下
import tensorflow as tf | |
import numpy as np | |
# create data | |
x_data = np.random.rand(100).astype(np.float32) | |
y_data = x_data*0.1 + 0.3 | |
#搭建模型 | |
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0)) | |
biases = tf.Variable(tf.zeros([1])) | |
y = Weights*x_data + biases | |
#计算误差 | |
loss = tf.reduce_mean(tf.square(y-y_data)) | |
#传播误差 | |
#反向传递误差的工作就教给 optimizer 了,我们使用的误差传递方法是梯度下降法: Gradient Descent 让后我们使用 optimizer 来进行参数的更新. | |
optimizer = tf.train.GradientDescentOptimizer(0.5) | |
train = optimizer.minimize(loss) | |
#训练 | |
#到目前为止,我们只是建立了神经网络的结构,还没有使用这个结构。在使用这个结构之前,我们必须先初始化所有之前定义的 Variable, 所以这一步是很重要的! | |
# init = tf.initialize_all_variables () # tf 马上就要废弃这种写法 | |
init = tf.global_variables_initializer() # 替换成这样就好 | |
#接着,我们再创建会话 Session. 我们用 Session 来执行 init 初始化步骤。并且,用 Session 来 run 每一次 training 的数据。逐步提升神经网络的预测准确性. | |
sess = tf.Session() | |
sess.run(init) # Very important | |
for step in range(201): | |
sess.run(train) | |
if step % 20 == 0: | |
print(step, sess.run(Weights), sess.run(biases)) |
tensorflow version 2 代码如下
import tensorflow as tf | |
import numpy as np | |
#creat data | |
x_data = np.random.rand(100).astype(np.float32) | |
y_data = x_data*01.+0.3 | |
### creat tensorflow structure start ### | |
Weights = tf.Variable(tf.random.uniform((1,),-1.0,1.0)) | |
biases = tf.Variable(tf.zeros([1])) | |
y = Weights*x_data+biases | |
loss= lambda: tf.keras.losses.MSE(y_data,Weights * x_data +biases) | |
optimizer = tf.keras.optimizers.SGD(learning_rate=0.5) | |
### creat tensorflow structure end ### | |
for step in range(201): | |
optimizer.minimize(loss, var_list=[Weights, biases]) | |
if step %20==0: | |
#print(step,sess.run(Weights),sess.run(biases)) | |
print("{} step, weights = {}, biases = {}".format(step, Weights.read_value(), biases.read_value())) # read_value 函数可用 numpy 替换 |
# Session 会话控制
这一次我们会讲到 Tensorflow 中的 Session , Session 是 Tensorflow 为了控制,和输出文件的执行的语句。运行 session.run() 可以获得你要得知的运算结果,或者是你所要运算的部分.
首先,我们这次需要加载 Tensorflow ,然后建立两个 matrix , 输出两个 matrix 矩阵相乘的结果。
import tensorflow as tf | |
# create two matrixes | |
matrix1 = tf.constant([[3,3]]) | |
matrix2 = tf.constant([[2], | |
[2]]) | |
product = tf.matmul(matrix1,matrix2) |
因为 product 不是直接计算的步骤,所以我们会要使用 Session 来激活 product 并得到计算结果。有两种形式使用会话控制 Session 。
# method 1 | |
sess = tf.Session() | |
result = sess.run(product) | |
print(result) | |
sess.close() | |
# [[12]] | |
# method 2 | |
with tf.Session() as sess: | |
result2 = sess.run(product) | |
print(result2) | |
# [[12]] |
tensorflow version 2 已经不需要用 session 控制了
import tensorflow as tf | |
matrix1=tf.constant([[3,3]]) | |
matrix2=tf.constant([[2],[2]]) | |
product=tf.matmul(matrix1,matrix2) | |
tf.print(product) |
# Variable 变量
在 Tensorflow 中,定义了某字符串是变量,它才是变量,这一点是与 Python 所不同的。
定义语法: state = tf.Variable()
import tensorflow as tf | |
state = tf.Variable(0, name='counter') | |
# 定义常量 one | |
one = tf.constant(1) | |
# 定义加法步骤 (注:此步并没有直接计算) | |
new_value = tf.add(state, one) | |
# 将 State 更新成 new_value | |
update = tf.assign(state, new_value) |
如果你在 Tensorflow 中设定了变量,那么初始化变量是最重要的!!所以定义了变量以后,一定要定义 init = tf.initialize_all_variables() .
到这里变量还是没有被激活,需要再在 sess 里, sess.run(init) , 激活 init 这一步.
# 如果定义 Variable, 就一定要 initialize | |
init = tf.global_variables_initializer() # 替换成这样就好 | |
# 使用 Session | |
with tf.Session() as sess: | |
sess.run(init) | |
for _ in range(3): | |
sess.run(update) | |
print(sess.run(state)) |
注意:直接 print(state) 不起作用!!
一定要把 sess 的指针指向 state 再进行 print 才能得到想要的结果!
附上 v2 代码
import tensorflow as tf | |
state=tf.Variable(0,name='counter') | |
one=tf.constant(1) | |
new_value=tf.add(state,one) | |
for _ in range(3): | |
#The variable value can be changed using one of the assign methods. | |
state.assign_add(new_value) | |
tf.print(state,new_value) |
# Placeholder 传入值
placeholder 是 Tensorflow 中的占位符,暂时储存变量.
Tensorflow 如果想要从外部传入 data, 那就需要用到 tf.placeholder() , 然后以这种形式传输数据 sess.run(***, feed_dict={input: **}) .
示例:
import tensorflow as tf | |
#在 Tensorflow 中需要定义 placeholder 的 type ,一般为 float32 形式 | |
input1 = tf.placeholder(tf.float32) | |
input2 = tf.placeholder(tf.float32) | |
# mul = multiply 是将 input1 和 input2 做乘法运算,并输出为 output | |
ouput = tf.multiply(input1, input2) |
接下来,传值的工作交给了 sess.run() , 需要传入的值放在了 feed_dict={} 并一一对应每一个 input . placeholder 与 feed_dict={} 是绑定在一起出现的。
with tf.Session() as sess: | |
print(sess.run(ouput, feed_dict={input1: [7.], input2: [2.]})) | |
# [ 14.] |
v2 貌似已经换掉了 placeholder ,看到我再添加。
# Activation Function 激励函数
这里的 AF 就是指的激励函数。激励函数拿出自己最擅长的” 掰弯利器”, 套在了原函数上 用力一扭,原来的 Wx 结果就被扭弯了.
其实这个 AF, 掰弯利器,也不是什么触不可及的东西。它其实就是另外一个非线性函数。比如说 relu, sigmoid, tanh. 将这些掰弯利器嵌套在原有的结果之上,强行把原有的线性结果给扭曲了。使得输出结果 y 也有了非线性的特征。举个例子,比如我使用了 relu 这个掰弯利器,如果此时 Wx 的结果是 1, y 还将是 1, 不过 Wx 为 - 1 的时候,y 不再是 - 1, 而会是 0.
你甚至可以创造自己的激励函数来处理自己的问题,不过要确保的是这些激励函数必须是可以微分的,因为在 backpropagation 误差反向传递的时候,只有这些可微分的激励函数才能把误差传递回去.
想要恰当使用这些激励函数,还是有窍门的。比如当你的神经网络层只有两三层,不是很多的时候,对于隐藏层,使用任意的激励函数,随便掰弯是可以的,不会有特别大的影响。不过,当你使用特别多层的神经网络,在掰弯的时候,玩玩不得随意选择利器。因为这会涉及到梯度爆炸,梯度消失的问题。因为时间的关系,我们可能会在以后来具体谈谈这个问题.
最后我们说说,在具体的例子中,我们默认首选的激励函数是哪些。在少量层结构中,我们可以尝试很多种不同的激励函数。在卷积神经网络 Convolutional neural networks 的卷积层中,推荐的激励函数是 relu. 在循环神经网络中 recurrent neural networks, 推荐的是 tanh 或者是 relu (这个具体怎么选,我会在以后 循环神经网络的介绍中在详细讲解).
# 创建第一个神经网络
# 例子 3 添加层 def add_layer ()
# 计算机视觉介绍
# Anaconda 使用
%config IPCompleter.greedy=True #按 tag 可以自动补全代码 |
# 加载 Fashion MNIST 数据集
70000 张图片
10 个类别
28*28 像素
训练神经元网络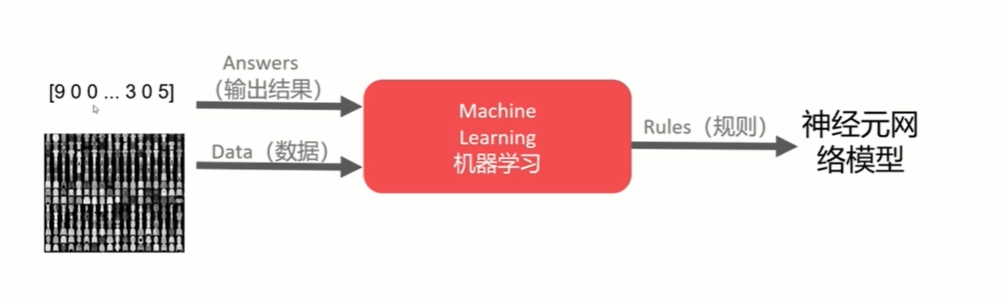
import tensorflow as tf | |
from tensorflow import keras | |
import matplotlib.pyplot as plt | |
#导入数据集 | |
fasion_mnist = keras.datasets.fashion_mnist | |
#划分数据集 | |
(train_images,train_labels),(test_images,test_labels) = fasion_mnist.load_data() | |
#看数据集大小 | |
print(train_images.shape) | |
#展示图片 | |
plt.imshow(train_images[1]) |

# 构建神经元网络模型
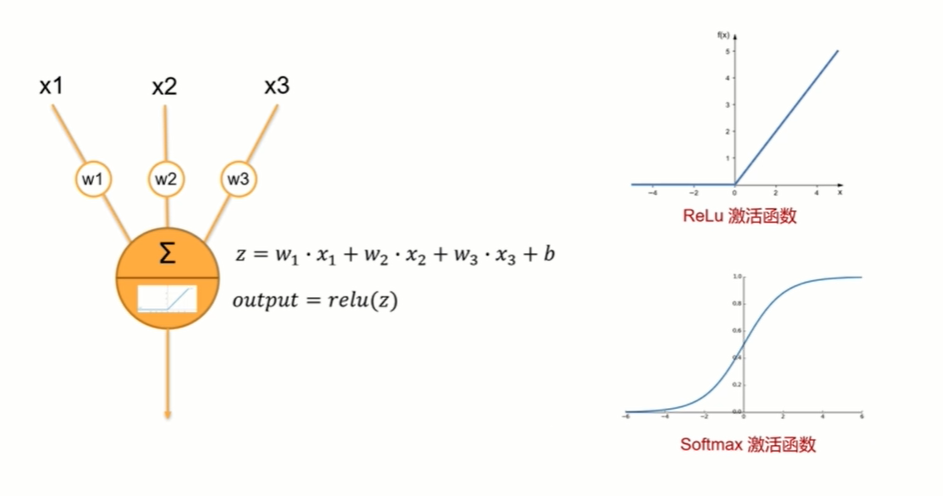
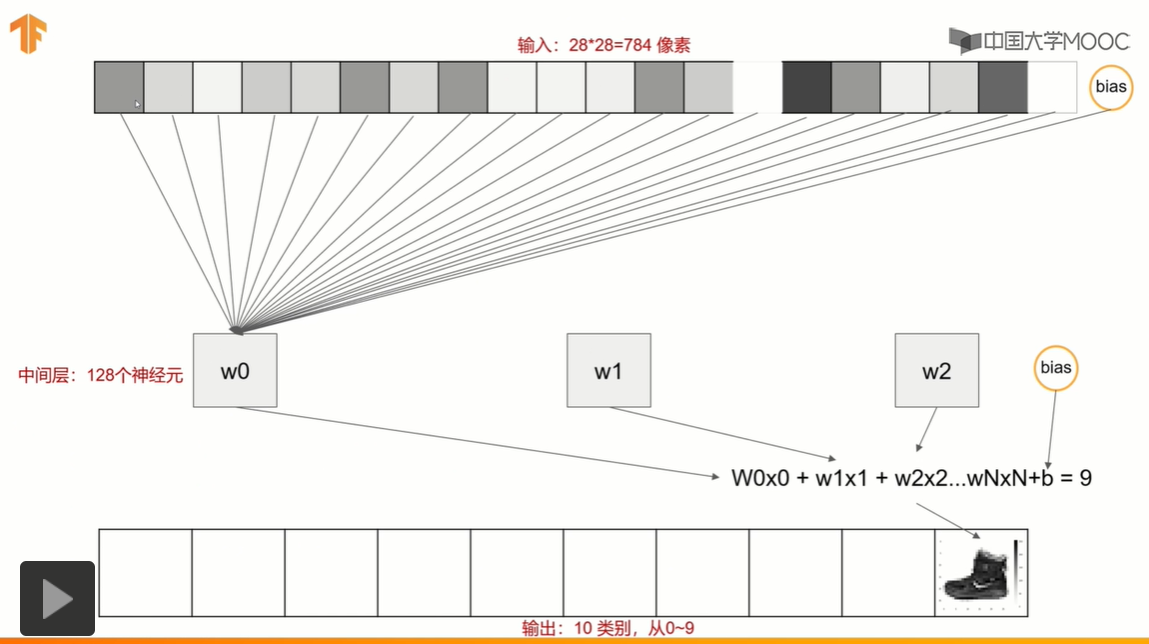
全连接的网络结构
model = keras.Sequential() | |
model.add(keras.layers.Flatten(input_shape=(28,28))) | |
model.add(keras.layers.Dense(128,activation=tf.nn.relu)) | |
model.add(keras.layers.Dense(10,activation=tf.nn.softmax)) | |
model.summary() | |
#以下为 console | |
Model: "sequential_1" | |
_________________________________________________________________ | |
Layer (type) Output Shape Param # | |
================================================================= | |
flatten_1 (Flatten) (None, 784) 个像素 0 | |
_________________________________________________________________ | |
dense (Dense) (None, 128) 100480 (784个像素+1权重)*128个神经元 | |
_________________________________________________________________ | |
dense_1 (Dense) (None, 10) 1290 (128个神经元+1权重)*10个类别 | |
================================================================= | |
Total params: 101,770 | |
Trainable params: 101,770 | |
Non-trainable params: 0 | |
_________________________________________________________________ |
# 训练和评估模型
#scaling or normalization 把灰度变成只有 1 和 0 | |
train_imges_scaled=train_images/255 | |
#metrics=['accuracy'] 是为了看到指标 accuracy 的变化, | |
model.compile(optimizer=tf.optimizers.Adam(),loss=tf.losses.sparse_categorical_crossentropy,metrics=['accuracy']) | |
#训练,epochs 重复次数 5 次 | |
model.fit(train_imges_scaled,train_labels,epochs=5) | |
#模型评估 | |
test_images_scaled = test_images/255 | |
model.evaluate(test_images_scaled,test_labels) | |
import numpy as np | |
print(np.argmax( model.predict([[test_images[0]/255]]))) | |
print(test_labels[0]) | |
plt.imshow(test_images[0]) |
# 自动终止训练

#重载一个 callback 方法 | |
class myCallback(tf.keras.callbacks.Callback): | |
def on_epoch_end(self,epoch,logs={}): | |
if(logs.get('loss')<0.4): | |
print("\n Loss is low so cancelling training!") | |
self.model.stop_training = True | |
callbacks= myCallback() | |
mnist =tf.keras.datasets.fashion_mnist | |
(training_images,training_labels),(test_images,test_labels) = mnist.load_data() | |
training_images_scaled = training_images/255 | |
test_images_scaled = test_images/255 | |
model =tf.keras.models.Sequential([ | |
tf.keras.layers.Flatten(), | |
tf.keras.layers.Dense(512,activation = tf.nn.relu), | |
tf.keras.layers.Dense(10,activation = tf.nn.softmax) | |
]) | |
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) | |
model.fit(training_images_scaled,training_labels,epochs=5,callbacks=[callbacks]) | |
---console:--- | |
Epoch 1/5 | |
1875/1875 [==============================] - 5s 3ms/step - loss: 0.4734 - accuracy: 0.8292 | |
Epoch 2/5 | |
1867/1875 [============================>.] - ETA: 0s - loss: 0.3585 - accuracy: 0.8697 | |
Loss is low so cancelling training! | |
1875/1875 [==============================] - 5s 3ms/step - loss: 0.3583 - accuracy: 0.8697 |